

2084: AI editing of documents and an automatic narrator
Recent papers on a model for generating and processing arbitrary documents, a model to provide automatic narration, a model for physics based animation and a model for more control over images


I saw an interesting paper on paperswithcode today. The paper was about a new transformer model architecture which processes arbitrary documents, not just text. How it does this is by taking the OCR of the document, and then taking the bounding box and layout of the text on the document, and embedding them in the token representation of the text which will be passed to the transformer architecture.
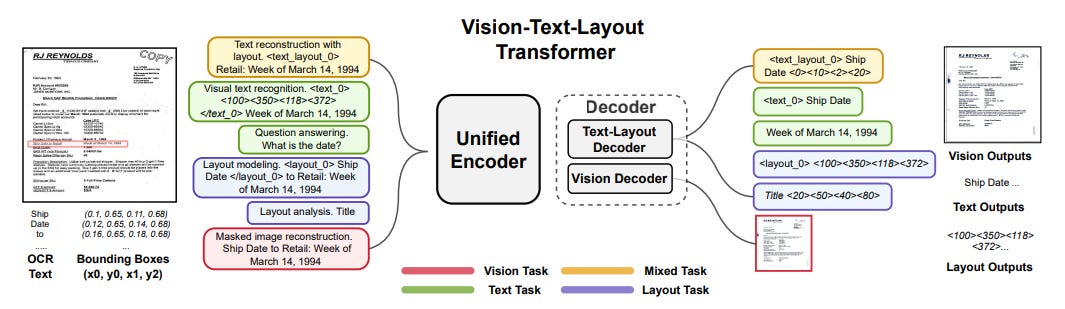
To explain more simply: All neural networks based on the Transformer architecture, which is the architecture powering most large language models, most of the big generative image models like Stable Diffusion and Midjourney, and most of the research coming out today, take as input a large amount of tokens. Now a token is a number that represents a single small bit of data, the unit of information that the model reasons on. How you split up and convert input data into tokens, and what data you choose to consider when calculating a token has a large effect on what your model can reason about, and generate. Now for most large language models, a token is just a number that corresponds to a syllable or word, that has been combined with a positional encoding to indicate to the model how the tokens should be organized. Think of the formula as the following: token = number corresponding to word + index of token. It is a bit more complicated than that, but the idea is that since Transformers have the attribute that the order of the input tokens is not explicitly given, you need to encode where it is in the sentence in the token. Now of course, what data you choose to encode in the token is arbitrary, and that of course is where the paper comes in - to put it simply, they added 2D position, and layout information to their text tokens which they feed to their transformer model.
Now the cool part about this, and the reason I found this interesting, is that by doing this, they can get their transformer to generate and edit parts of a document in such a way that it looks entirely natural, as well as extract and classify arbitrary parts of a document:

Given how much documentation there still is going around, this could be a very practical model to use. The fact that it encodes layout however is most interesting to me. Of course this is just for documents, but imagine if you could use the same technique, together with something like Stable Diffusion, to automatically generate fully edited and authentic PDF documents promoting your business, or a containing a fully written report on whatever you wanted to have done. It could be not too soon before very large language models exist which can generate documents instantly of whatever type, length and content you want.
Another interesting paper, which shows how much consistency and control people are starting to get from these large generative models, is Paint By Example, which is a model where you can give a variant of Stable Diffusion an examplar image and a background image with mask, and it’ll insert the one into the other. It’s quite controlled and a really good way to edit the generated papers. There is a demo linked in the paper, if you want to try it out:

There’s also ReAtt which is a paper on a Transformer architecture for retrieving an article from a very large dataset, processing it, and answering accurate questions about it. It’s fascinating, since the rumor mill has it that GPT-3 will soon have it be connected to the web so it can fact check answers, and this architecture shows that that is entirely possible and effective.
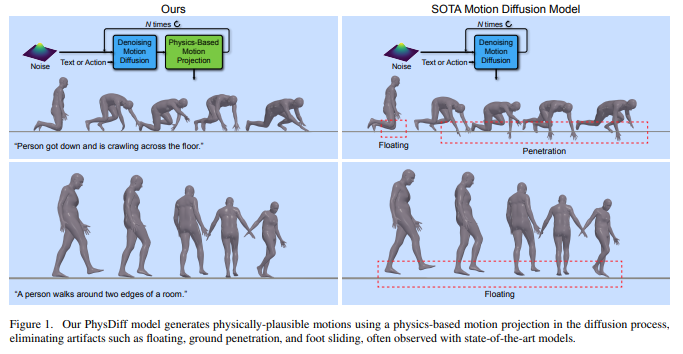
And of course, as I did talk about automatic animation creation a while back, there’s a new paper out where they’ve modified the motion diffusion model to take physics into account, leading to more accurate results across the board. Soon, there won’t even be any work left to do in animation, which is an interesting thought.
And finally, there’s LAVILA, which is an architecture built on GPT-2 that takes in videos and outputs an auto narrator for those videos describing what they do and how. Beyond being quite useful, it also further indicates the generality of these large models - with a bit of modification and further training, they seem to be able to do nearly anything you would want them to do, which is something that is quite humanlike.
Now these are all just applications, but they are a wide range of applications, and they are showing more and more the breadth of these new models. Given models like GATO which can do multiple things at once, these tools will become more and more widespread. In the end, your entire laptop in 2084 might just be a fancy websocket to a big LLM, with a variety of submodels running on top of it, generating documents, animations, or narrations.
