
2084: BitNet overhyped? Training BitNet Mamba on the Tiny Shakespeare dataset
Applying single bits to solve my problems.

Recently, I came across a fascinating paper called BitNet, which proposes a novel approach to making neural networks more inferentially efficient. The core idea is to quantize the linear or matrix layers in a model to use only single bits, which can lead to significant improvements in performance.
To understand the significance of this, let's take a closer look at the architecture of a typical transformer network. The self-attention blocks, which are the heart of the network, consist of matrix multiplications between the input, query, and value matrices (Q, W, and V). These multiplications are computationally expensive, making up a large portion of the model's parameters.
The BitNet paper tackles this issue by applying quantization to the weights and activations in the linear layers during inference. This involves replacing the original weights with a quantized version, calculated using the following formula:
u = W.mean()
s = W.abs().mean()
W_q = (W-u).sign()*sSo essentially at the end you end up with a matrix that consists of positive or minus s, which can be represented as the product of a matrix of positive 1 or negative 1 and s, which is much smaller than a matrix of numbers, seeing as s is the only full precision number, and the elements of the matrix itself, being only 1s and -1s, can be stored in single bits.
For the activations it just takes the activation vector x and reduces the range to be an integer in [-127, 127].
x_q = ((127.0/x.abs().max())x).round()For the inference itself it just calculates:
However, if you just wrote this, it wouldn’t work - the gradient wouldn’t be able to calculate the weights before quantization properly.
Thus what they do(and this is what they refer to as the STE or Straight Through Estimator in the original), is the following, where weight_quant is the above function:
w_q = w + (weight_quant(w) - w).detach()Now what the detach() operation does is it essentially marks the operations as being invisible to the gradient calculator - it detaches them from the computation graph. This is necessary as sign is not a differentiable function. Thus for the purposes of the gradient, it acts as if the quantization never happened, however, since it is still active on the forward pass, the quantization outputs are still fed into the other layers for the calculation of their gradients, and thus the network learns to cope with the quantization. This means however that you really need to perturb the weights to have the quantized weights change and so you generally need a higher learning rate to train a bitnet model.
It does the same to the activations
x_quant = x_norm + (activation_quant(x_norm) - x_norm).detach()Now since this is essentially just a minor change to the linear layers in a model, there’s no reason that you can’t apply this to all the linear layers in a Mamba architecture.
To put it all together, what the bitnet does is it replaces the linear layers with the following:
class BitLinear(nn.Linear):
def forward(self, x: Tensor) -> Tensor:
w = self.weight
x_norm = SimpleRMSNorm(self.in_features)(x)
# Activation Quantization Calculation
scale_a = 127.0 / x.abs().max(dim=-1, keepdim=True).values.clamp_(min=1e-5)
act_q = (x * scale_a).round().clamp_(-128, 127) / scale
# Weight Quantization Calculation
scale_w = w.abs().mean()
e = w.mean()
weight_q = (w - e).sign() * scale_w
# Straight Through Estimator Magic
x_quant = x_norm + (act_q - x_norm).detach()
w_quant = w + (weight_q - w).detach()
y = F.linear(x_quant, w_quant) # x_quant @ w_quant
return yA 14 page paper about ~14 lines of code. Such is the machine learning space.
By applying the BitLinear layers to the Mamba architecture, you get the BitMamba architecture, which is just the Mamba architecture with all the linear layers changed to use the BitLinear architecture.

Now just for fun, I’m going to apply BitMamba to the tiny Shakespeare dataset, and compare using Mamba vs BitMamba in terms of speed of convergence and loss graph, as well as final inference speed. I’m using the implementation in this github repo as a big reference - big shout out to kyegomez!
For the model itself, I’m using a variant of Karparthy’s NanoGPT, where tokenization(how the input is broken apart) is applied on a per letter basis. I’m also running it for 5000 iterations.
The colab is here.
BitMamba
Hyperparameters
lr = 1e-3
batch_size = 32
block_size = 256
device = "cuda" if torch.cuda.is_available() else "cpu"
max_iters = 5000
print_iters = 100
eval_iters = 10
eval_interval = 300
n_embed=384
n_heads = 6
n_layers = 6
dropout = 0.2At 0 iterations:

At 1000 iterations:

At 2000 iterations:

At 3000 iterations:

At 4000 iterations:

At 5000 iterations.

The final loss graph:

It still has some way to go but it’s pretty slow as far as iterations go.
Now testing the Mamba
Mamba
Hyperparameters
lr = 1e-3
batch_size = 32
block_size = 256
device = "cuda" if torch.cuda.is_available() else "cpu"
max_iters = 5000
print_iters = 100
eval_iters = 10
eval_interval = 300
n_embed=384
n_heads = 6
n_layers = 6
dropout = 0.2At 0 iterations:

At 1000 iterations:

It’s converged so much quicker to legible English with equivalent test loss and train loss to BitMamba after 1000 iterations. After this it went on to train a bit more, where at some point it saturated.
The following is the loss graph for BitMamba:
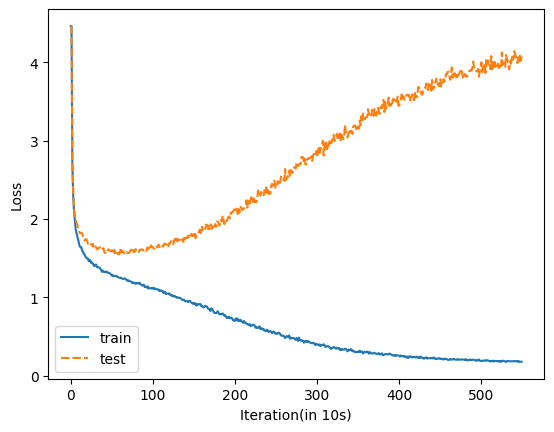
Now the test loss does go up quite rapidly after 1000 iterations, however, it reaches the same point that the BitMamba does so much quicker that I would rather use the full linear layers than the BitMamba. In addition, I expected the model to overfit given the small size of the dataset.
However, BitMamba is just too slow - it took 5 times longer to reach the same point that the Mamba network did and qualititavely it never produced anything close to readable English. The only difference between the two networks in addition is that the one used linear layers and the other used BitLinear layers - all the hyperparameters were the same.
I think this might be due to the STE part - it’s not entirely clear to me how the gradients can change the weights in a way that respects the quantization operators if you completely leave out the quantization operators, and the slow rate of convergence confirms that to me. I think from a practical standpoint, that training a Mamba network on a dataset and then quantizing it, you’re probably likely to get more bang for your buck, especially given how compute is become ever cheaper and more commodized, and the real constraint will increasingly be time.
I want to run some more experiments, maybe seeing how BitTransformers compare against regular transformers, but I think my conclusion for now, is that BitNet has been a bit overhyped.
I’d love any inputs into what I should look at next with my small models!
What do people think about bitmamba?