

2084: Editing the Facts
Rewriting a language's model neural network to correct or change facts


Now, it is commonly asserted that a LLM is entirely a black box, that there’s no way to know exactly what’s going on when you prompt it to give some specific thing. This, however, like a lot of commonly known facts is only half true. There are ways in which we can edit and change the facts that a LLM stores, by making localized edits to a specific group of neurons.
First there is ROME. ROME first identifies where the important neurons for a fact like “The pyramids are in Egypt”, by running the LLM twice, first letting the LLM predict the next word in the sentence “The pyramids are in”, then recording all the intermediate steps, and then secondly adding noise to the input and running it through again, to see what the difference between the clean and corrupted runs were, with the neurons that were most different being the most important for the fact.
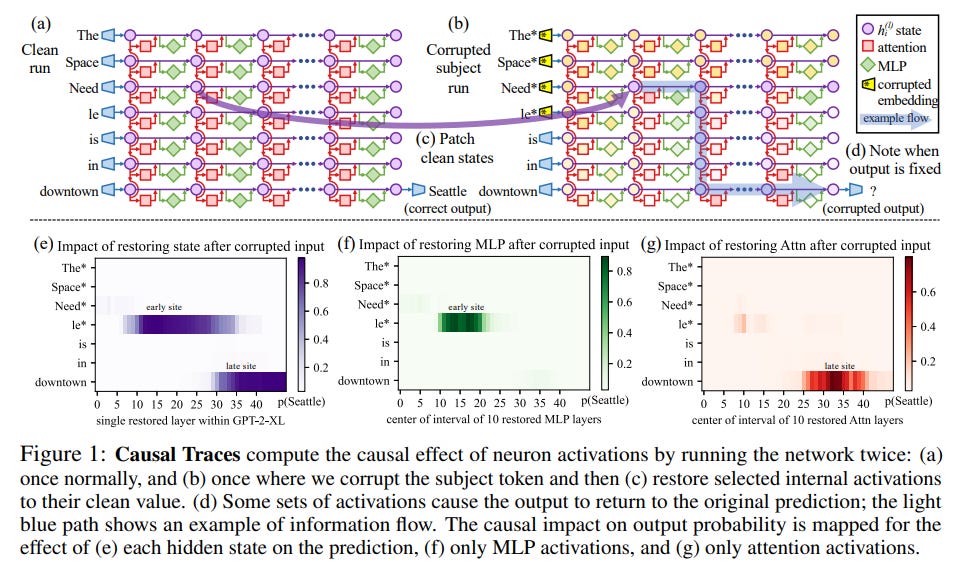
Then once you’ve found a layer, then by solving two constraint problems detailed in the paper, you can find a new key-value weight pair to insert, which will select the fact desired when you run the transformer. It’s quite smart and will definitely be used in the future to fix errors in systems like GPT-3.
But the researcher Meng, then decided to take it a step further, and released MEMIT, which is a mass editor of a LLM, which can insert or change many facts at once, instead of just one at a time like ROME. It' works very similarly, except that it edits a range of layers, and the constraint problems are different.

The papers are well worth reading, and fascinating in what they say about how information is stored in these models, and also how the issue of inaccuracy could be fixed. There is another paper which is also interesting, about how it may not matter as much which layers you edit exactly, but even so, the technique is still useful. It can’t be too long before the models become like Wikipedia, a place where anyone across the world can contribute their knowledge. In 2084, all these models may be both verbose and accurate. It’ll be an awesome world.
