

2084: Expert Diffusion - eDiff
Different Denoisers at Different Noises


So I was looking at an interesting refinement of the diffusion model paradigm eDiff. So basics of diffusion models: Diffusion models are trained to remove noise from images. When you feed them pure noise, they generate an entirely new image by removing “noise” from the pure noise. You can add in some additional data to guide them during denoising to produce specific instances.
Now most diffusion models use the same model at all steps of the denoising, however eDiff decided to see whether better results would be achieved if different specially trained diffusion models would be used at each denoising step, models which would be trained specifically for the corresponding level of noise.
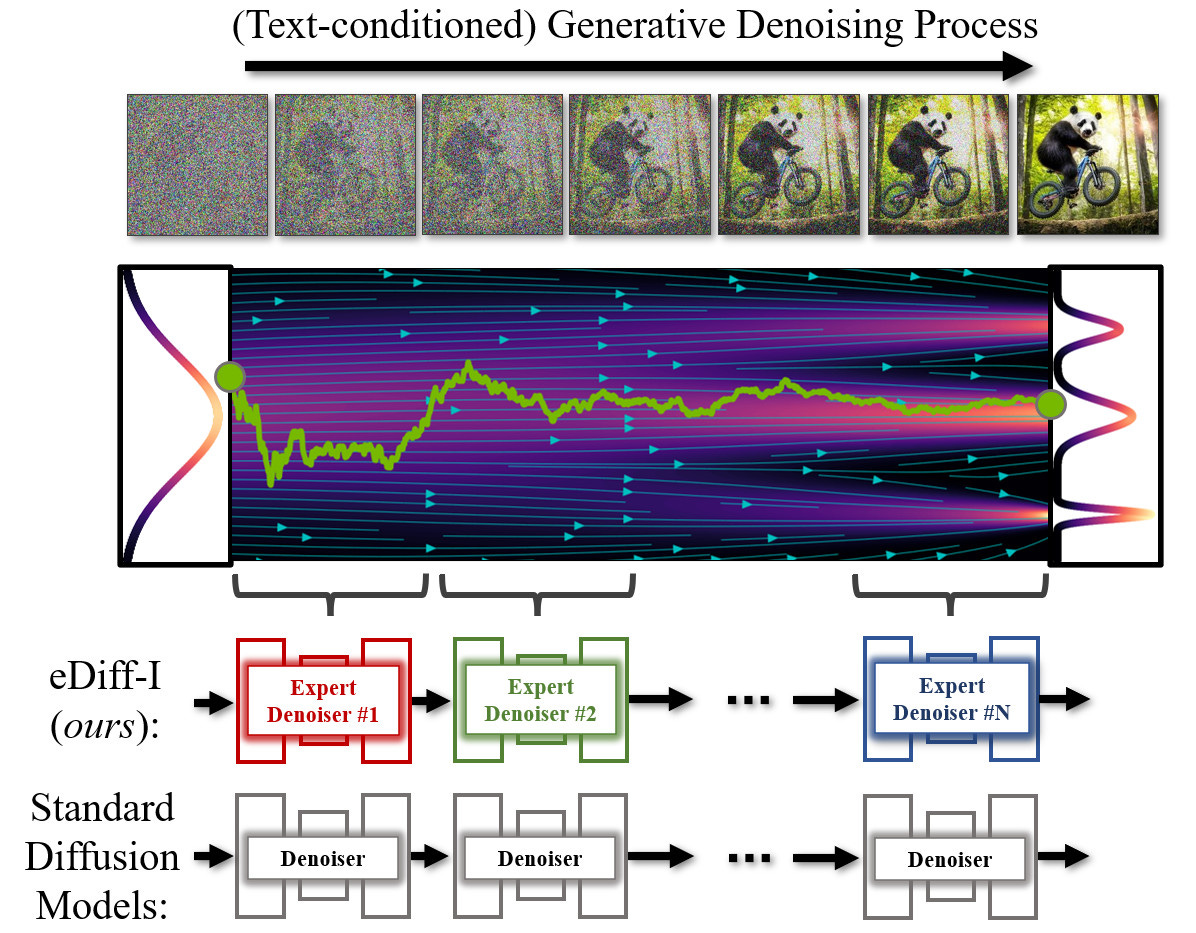
The paper claims that this results in a much better output versus other diffusion models which you can judge for yourself.

In addition, instead of using a single encoder like most other diffusion models, it uses an ensemble of encoders which can therefore accept different types of input which can all be considered at different stages to produce images that are more closely mapped to the style you would like. This is quite useful since an issue with a lot of diffusion models is stability, and this enforces a quite large level of stability. It’s not a massive leap forward, but it is part of the process of making diffusion models more and more usable for everyday business tasks.
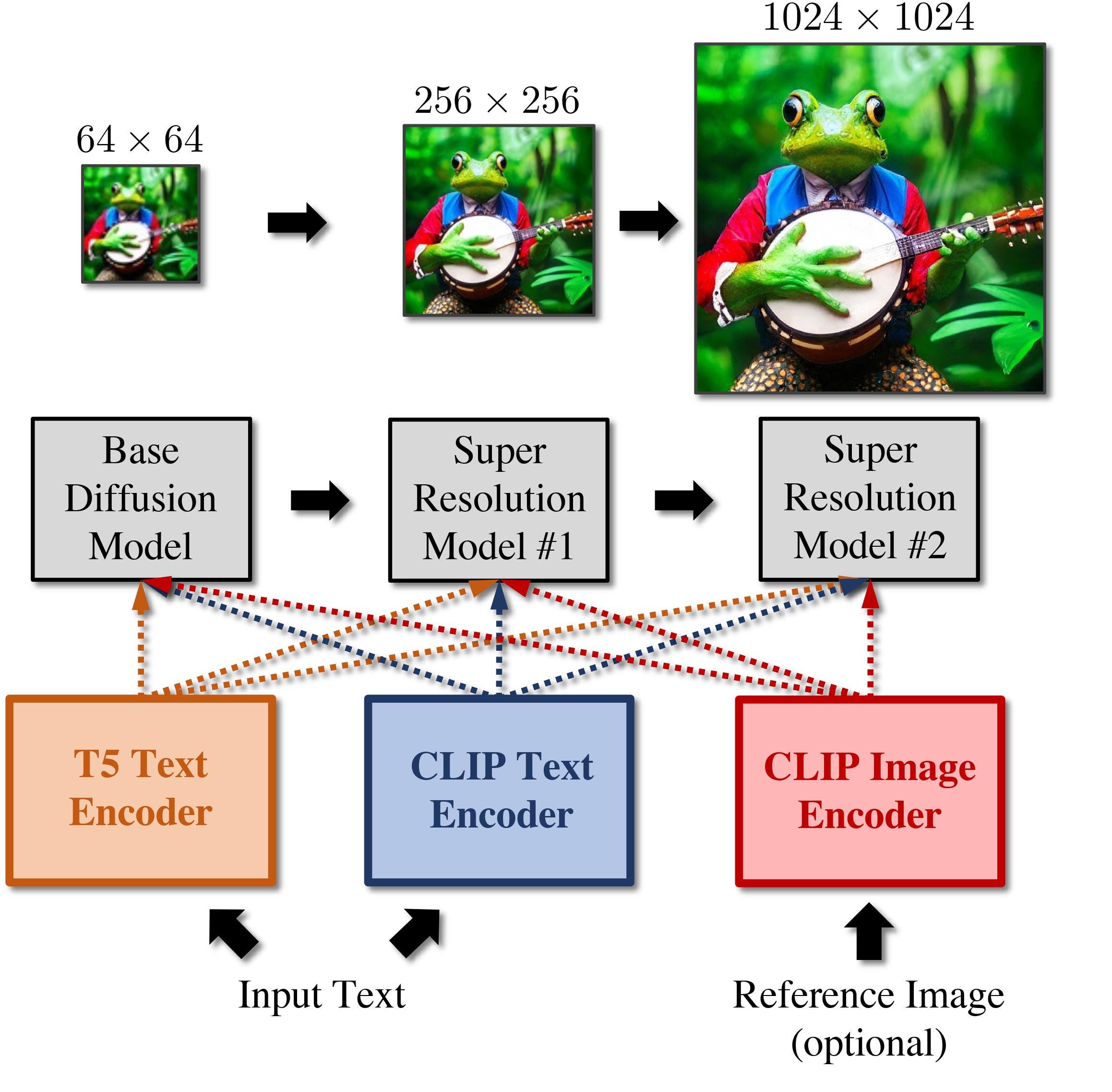
I already believe that in 2084, we will be using these art generating diffusion models for everything, and I see this as being another step on the process of making it easier to control, and more useful. There’s also work on easily modifying existing images which is also already useful. To quote Two Minute Papers, what a time to be alive!
