

2084: How does Image Generation AI work?
Some explanation and exploration of image generation AI


Image Generation AI models are all the rage these days, ever since the original Dall-E 2 paper came out and showed that guided diffusion models are both possible and high quality. Especially lately with models like Midjourney 4 coming out, and producing absurdly high quality images, it’s been looking more and more like these models will be an increasingly larger part of the future of creativity.
Now this post is essentially going to be a brief and simple introduction to the basic behind guided diffusion models, which is what the tech behind Dall-E 2, Midjourney and Stable DIffusion is, followed by a brief look at these 3 models and what they do.
First, diffusion models. A diffusion model is essentially an AI model which removes noise from an image. It does this by repeatedly processing an image to predict the inverse of the noise in the image , which it then subtracts from the image, and repeats until there is no more noise left in the image. Now, you might wonder how this can generate images. The magic is that essentially, if you feed pure noise, which looks like the following rightmost image, it will also remove noise from this pure noise, and the result is an image. Essentially, it sees patterns in pure noise which correspond to the patterns in the noise obscuring an image, and obviously, when you reverse the noise of an image, you get a new image. This is the essence of the diffusion model.


Now, how it’s trained is that you take a normal dataset of images, you take an image, progressively add noise to it(as in the picture of the cat above), and then compare your models output for each iteration against the known inverse of the noise you added to the image. Do this for all the images, and you have a fully trained denoiser, which will happily generate another instance that looks very similar to the data in the dataset. Of course there are a lot of implementation details with regards to how you do that, and the exact neural network you use for the denoiser, but that can be found in this quite useful tutorial.(As an aside, here’s a good article on transformers) Stable Diffusion and Dall-E use a network called a U-Net, which looks like the following:
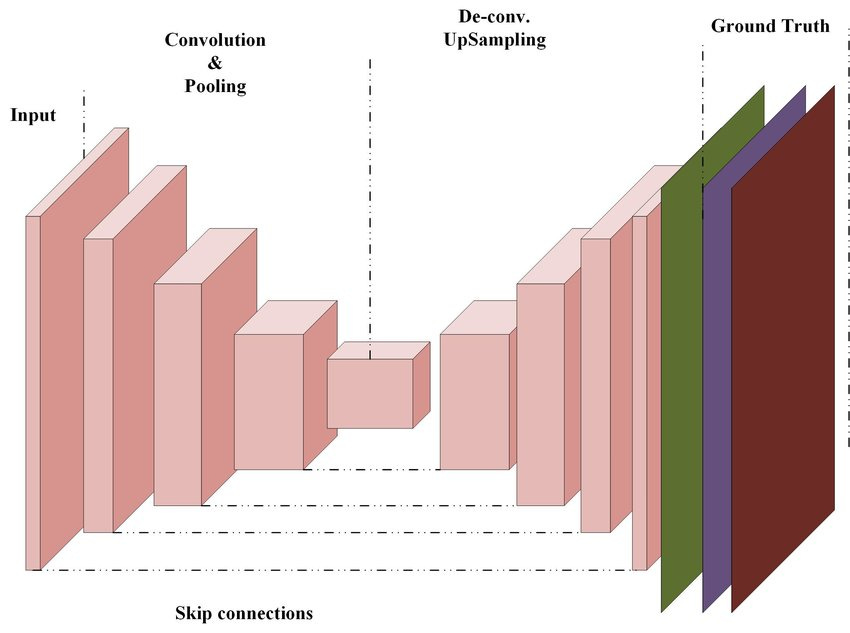
Now if you just use this to create a diffusion model, your resulting images will be random as the noise used was random. However, the trick that the Dall-E 2 paper used for guiding the diffusion was that they added an additional parameter into the model, y which was an embedding representing the caption of the image, which they obtained from another model called CLIP. Therefore now the model, lets call it theta(image,t,y) at each step, produces not just the inverse of the noise of the image, but the inverse of the noise of the image with the caption given.
Now therefore if you feed it pure noise with a caption, it’ll produce inverse noise with reference to the the caption you give it, and so you’re essentially bounding which patterns it sees in the noise. And that’s how the magic of Dall-E 2 is done - the caption essentially forces the model to create the inverse noise of images associated with the caption, which is usually what you want when you want an image of a caption generated.
There are quite a lot of ways to improve this, with Stable Diffusion for example essentially using a network called an autoencoder to make the input image smaller by embedding it in a lower dimension and then reconstructing the output to the higher dimension but they all use the same basic idea.
Now the 3 main and accessible Text 2 Image AI’s that exist are Midjourney, Stable Diffusion and Dall-E 2.
Dall-E 2 is the original and uses the ideas described above. It was trained on standard images and captions scraped from the internet. It tends to be rather literal in interpreting the prompts you give it, and the dataset doesn’t appear to have been curated overmuch, but you can get some really nice pictures from it.

Then you have my favorite, Midjourney. As far as I know, Midjourney also uses the same architecture as Dall-E 2, but where it differs is the dataset - Midjourney was trained on much more artsy images, and thus generally has a more artistic style. It’s free for the first 50 images or so, but the subscription for quite a lot of images is only $14 a month, which is well worth it.

And then there’s the open source version Stable Diffusion. Stable Diffusion is significantly smaller than the other two, and is therefore capable of being run on most normal computers. Since it is open source it also has a much bigger tool community than Dall-E 2 or Midjourney - if you can think it, there’s probably a Stable Diffusion tool for it. Since it is smaller tho, it does tend to have a bit more artifacts then the other two. There’s a pretty neat blog dedicated to tools and such for Stable Diffusion, which is well worth checking out. The fact that it’s open source, means also that you can train the image model to be specific to your use case, which means that Stable Diffusion is much more general and therefore more likely to be more widely used than the other two - it’ll probably be the basis for most AI image tools you see. And of course, there is a NSFW version, Unstable Diffusion, which I won’t link to.

But anyways, there’s a lot more models out there like Imagen and such, and this is barely scratching the surface. I think that these AI models will be transformative. They are genuinely creative, quick to use, and getting more and more consistent with every update. Soon any art task you could think of will be done by these AIs, and it’ll be done well. The job of an Artist could very well change to being a AI Technician and Prompt Engineer. In the year 2084, we might not even understand the profession of an artist, or it might be seen as craftsman making articles by hand are seen today. The tyranny of talent might finally be broken, and art might become finally, completely democratized, for good or for bad.

Nice one. Very interesting indeed. So our entire neural net is just a noise removal mechanism. Who knew!?