
So after spending my whole summer doing AI stuff, I have now achieved a vague understanding. So therefore, I’ve been thinking a lot about text to image generation. Namely the text in text to image generation

This is a random diffusion model generated thing I found, generated with midjourney. Notice that the text is random. This is a big obstacle to design of stuff like posters with midjourney or dall-e 2. The technical explanation is that it presumably uses CLIP - basically CLIP is how diffusion models know what imagery is related to the text they use, and CLIP as used in midjourner presumably and stable diffusion is not a very large network and therefore doesn’t encode enough information to reliably generate text.
Then I found Gligen.
GLIGEN:Open-Set Grounded Text-to-Image Generation.
Gligen

Gligen basically lets you draw these bounding boxes along with text associated with the bounding boxes to determine where the objects in the resultant image would be. They used computer vision to get the original bounded boxes.
Now I thought, hey, what if instead of computer vision, I use OCR? Then I could get bounding boxes + text for the text in an image, then you could draw little boxes with text and get a beautifully crafted image.
So I started looking into it.
First things first: Transformers how do work?
There’s a lot of confusion about this point. But essentially, a transformer calculates overlap between all things in a set and then sums it all together to get a set of vector that encodes the importance of things in the set.
Basically:
Consider the following series of vector inputs:
X = [x_1,x_2,x_3, x_4]
Now consider that to get the next vector in the sequence, you don’t just want to consider x_4, you want to consider all the vectors in the sequence.
What’s an easy way to do that? Weighted sum ofc. Call this new vector w_n
You want this for each n, and this basically boils down to matrix multiplication. Call A the matrix of a values. Then:
But weighted sums are not great since they exploded. Thus you normalize, and that’s where the softmax comes in:
Basically its a sum with normalize of a multiply. Thus
Then you take this O, and you multiply it with the X to get a weighted set of inputs wrt how important they are.
And usually, you don’t just take the X straight and the A constant, but you map an input X into K and Q and V matrices using a standard many to many layer. This just makes it more expressive. So basically:
And then you make it multiheaded with is just many attn concated together:
And then you add the residuals so:
Cross attention is where you you use some external c input to generate Q.
Now what Gligen did was the following:
Consider that a stable diffusion transformer block consists of a self-attention and a cross-attention block which is basically the following two equations:
c is generated by applying CLIP to some text to get an embedding.
Now Gligen introduced some grounding inputs into this, with the following equation
This is inbetween the self attention and cross attention blocks. TS is token select i.e. you take the first len(v) columns of each attn in the SelfMultiAttn block to get a result which is similar shape to v.
Basically the grounding inputs were text and bounding box, and they used CLIP to generate an embedding from the text, which the concatted with a Fourier embedding for the bounding box.,
Fourier embedding looks like:
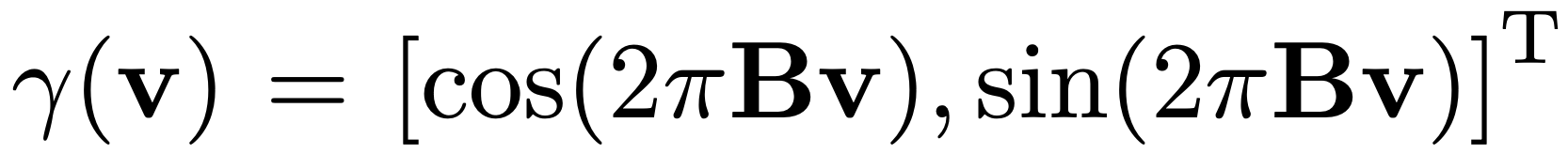
B is the weight matrix. This encodes a small dimension v into a big dimension y(v).
Now apply a multilayer perceptron(a few fully connected laters to [Clip(text), y(bounding box] to get the h^e tokens for the original.
And then you train it a lot like the original.
Now my idea is to train a new CLIP with (photo of text, text) pairs gotten from an OCR model and then use this + OCR to get the bounding box(look into GLIP), and then use the gligen model to inject into Stable Diffusion.
First step is to get a dataset together. I think it would be most sensible to start with single words since the possible set of possibilities is much much smaller. Get a dataset of images, run pytesseract on them to get the words and then train CLIP, call it TLIP, and put it into Gligen. Will this work? Lets find out.
Let’s make 2084 today.
CLIP Sidenote:
CLIP works by taking two embedders, one for text and one for images, and having the loss function be to maximize the cosine similarity between the output vectors. Basically matching up the embeddings to be sensible.
Welcome back dude!