

2084: Tuning Videos, Predicting the Weather and much more
Some interesting papers


So I read this interesting paper called Tune A Video, which essentially describes a way by which you could use existing text to image models to modify an video, by modifying how the internal “memory” or attention rather is kept to ensure greater consistency across generated video frames.

The results are quite striking, and it’s not too hard to see that this could easily become a part of a visual effects teams toolkit, especially if its extended a bit more. Would recommend reading the paper since it’s also a good view into how to modify the internal workings of a transformer to produce better results.
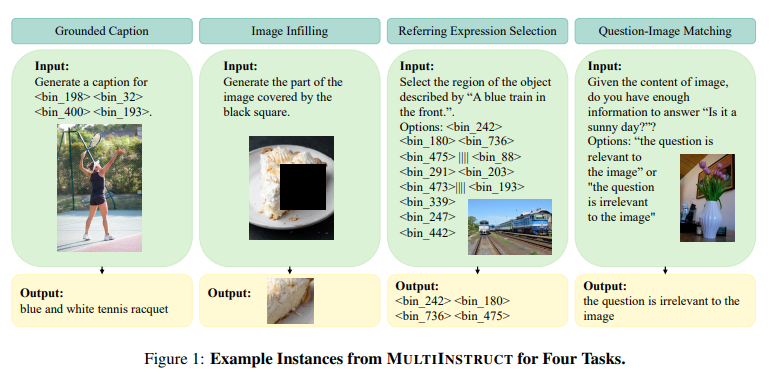
In addition, there was another interesting paper, MultiInstruct, whihch set out how it created a diverse set of tasks for a pretrained model to complete, and how it managed to create a multimodal model to do all of those tasks accurately. Like GATO and the others covered before, this is another example of how truly generalizable these large models are - they seem to be able to do pretty much anything.
And last, there was an interesting paper I read called Graph Cast where they used a Graph neural network to predict the weather. It was interesting especially since it indicates how by using a graph neural network or similar, you can perform inference across an input dataset across much larger distances - 10 million points and the like. Since that’s what you probably need to produce good audio, it bodes well for being able to produce music in the future - we might see some odd adaption of the transformer architecture that uses a variant of a graph neural network as its attention mechanism.

All the papers coming out are so interesting and varied that it seems like there’s barely a single task under the sun(a single task described by information at least), that can’t be done in some way by machine learning models using the new architectures of transformers and diffusion models. We live in exciting times and in 2084 it might be even more exciting.
