

2084: Variational Autoencoders and where ChatGPT gets its data.
Some notes on these models


For a project on whether the weights of a neural network lie on a lower dimensional manifold, I’ve been training up these structures called Variational Autoencoders. In the end I want to be able to generate 80% accurate weights for a small MNIST network, as a small proof of concept that there exists some fundamental structure of neural networks weights.
Now an autoencoder is an interesting concept. Most generative models are some variant of an auto encoder. An autoencoder is a neural network that takes in a specified input, and then tries to return the same input. But the trick is that there’s some bottleneck in the neural network, where you force some information to be lost. And so you try to see how much information you can throw away, and still be able to accurately reconstruct the original data. The amount of information you can throw away determines the size of the underlying structure of the data.
Now usually an autoencoder is divided into two parts: an Encoder and a Decoder. The encoder is a neural network that “cuts” away information. It’s usually implemented as a network that accepts a n dimensional vector and outputs a n-m dimensional vector. The decoder takes the cut down vector back to the "original" space, and takes in a n-m dimensional vector and gives you back an n dimensional vector. The space in which the smaller n-m dimensional vector sits is called the latent space of the dataset.

Now a basic autoencoder with no restrictions on the latent space is really bad for generation of data, since the space is not complete, generally - there are a lot of gaps in between points in the space, and so it’s not generally possible to interpolate or sample from this space. So for this purpose, there are a lot of variations on the autoencoder which add more restrictions on the latent space. A really useful variation is the so called Variational Autoencoder where the latent space is constrained to be as similar as possible to a n-m dimensional Gaussian distribution with a certain fixed mean and variance. The use of this is that this is a complete space which is sampleable, and thus by sampling this distribution, and passing it through the decoder, you can create a new example of the original data. For a good implementation, see this post.
So that’s essentially what I’m using to regenerate my model weights, a Variational Autoencoder. If that doesn’t work, I’ll try a diffusion model next - its quite similar, but a variational autoencoder is one shot, while a diffusion model is iterative and thus potentially more powerful.
And now for something completely different. There was an absolutely fascinating article I read on jilltxt which looked at the data on which GPT-3 was trained.
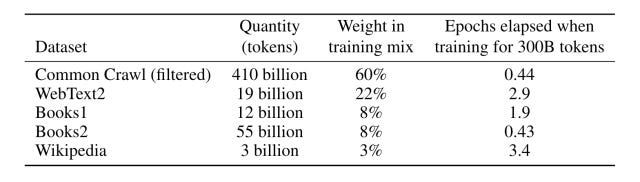
A token here refers to the smallest unit of text that GPT-3 is meant to be able to produce - usually a word, but it can be a syllable or a symbol or something more complicated. Usually you can deterministically produce tokens from a certain block of text.
Now there are essentially 5 datasets which GPT-3 has been trained on, Common Crawl, WebText2, Books1, Books2, and Wikipedia.
Common Crawl is a massive open source directory of petabytes of information scraped from the internet. It contains 3.15 billion web pages or 380 TiB of uncompressed content in its newest scrape in October, with page captures from 1.3 billion new URLs. It contains raw web page data, extracted metadata and text extractions. If you’ve ever wondered how GPT-3 knows about something relatively obscure or some odd part of programming or the internet, that’s probably Common Crawl - multiple petabytes of webpages across 40 languages will probably contain nearly anything you could possibly think of.
Then there’s WebText2. Like Common Crawl, it’s scraped from the internet, but its from webpages from outbound links from Reddit, which received at least 3 karma to ensure some level of quality, which is why it has a higher weight in training. This could also explain why on some weird level, ChatGPT sounds like a redditer in a lot of ways - it’s been trained on all the data read by redditors.
Not much is known about Books1, or Books2, besides that they are relatively large corpora of books. Presumably its something like Project Gutenburg, or BookCorpus. But the low weight is interesting. Presumably they were used to improve grammar and expand the knowledge available, but the dataset clearly shows that GPT-3 was always intended for the internet.
And of course, there’s Wikipedia. Wikipedia is interesting because it explains how ChatGPT can support such a wide variety of languages. I’ve tested it with some friends in Armenian, Hebrew and Afrikaans and the generated output was relatively readable, despite Armenian and Afrikaans not being very widespread languages. I suspect the large amount of multi lingual data on Wikipedia contributed greatly to the multilingual ability of ChatGPT.
Elon Musk in a tweet also said that Twitter had been a source of data for OpenAI, but its influence on ChatGPT isn’t known as far as I’m aware.
Now this dataset is fascinating. Its very very webfocused, with a lot of influence from Reddit, and is obviously very broad. It explains why OpenGPT sometimes sounds like a Redditor, with access to Google. And of course, it explains why it can do the weird things people have been getting it to do.
Now, GPT-4s training data hasn’t been released yet, but there’s been a lot of data scraped on Common Crawl since 2020, and there’s presumably more data out there that the model can be trained on. It’ll be interesting to see if in the future, in 2084, the information can be made even more broad, and of course, if it’ll be more and more accurate if its been trained for longer.
Now given that WebGPT has been out for a year, and that’s a model which can connect to the internet to verify its responses and get more accurate information, in the future, GPT-3 could be more dynamically grabbing training data from the internet rather than statically trawling through the dataset. Imagine a model that instantly grabs any information you want from the entire web, with sources and a summary. It would kill Google. As it is, it’s already a good competitor for Google. Maybe in 2084, search engines will be like pagers - a technology from the time before we had something better like cell phones.

Good meat here! Fascinating stuff...