
2084:Music Generating AI

While writing my application for the Light fellowship, I came across an interesting article on PopMNet, which was an approach to generating popular music by having an AI learn to generate the structure and melody for popular songs, since most pop music is so internally similar. It cited a few other projects on the artificial creation of music which I hadn’t seen before, namely Music Transformer and SaShiMi. Now both of these have different approaches to solving the long distance correlation problem, which is the central issue that needs to be solved to be able to generate the vast amounts of information needed to create pleasant sounding audio as waveforms contain a lot of information.
Now Music Transformer is quite interesting. It solves the long distance correlation problem by adding in relative position attention, where there can be long distance pairwise attention being present, with some smart optimizations being done so that the storage cost of storing all possible pairwise combinations isn’t too extreme. They provide a quite handy and quite nice sounding visualization of what they do in the following video. It’s quite interesting, and the paper itself is well worth reading, and it sounds really good.
Then there’s SaShiMi, which is a pretty good waveform generator that sounds really convincing when it comes to music when its generating raw audio waveforms. It’s based on state space models. Now state space models are often used in control theory. Essentially, you have a input vector u which you map to a latent representation x, where the following two equations with regards to the change of x and the output vector y hold:
Now A,B,C,D are taken as parameters to be determined by gradient descent. This model by itself is not accurate enough however to be used to learn most tasks in machine learning, and thus a modified version, called the discrete-time SSM, where a step size delta is introduced that represents the resolution of the input, and the SSM converts a input sequence to an output sequence. In addition, some strong constraints are placed on A to make it more amenable to analysis, and an approximate state matrix A overline is used instead of A as a target to learn, eith the following equations being in effect:
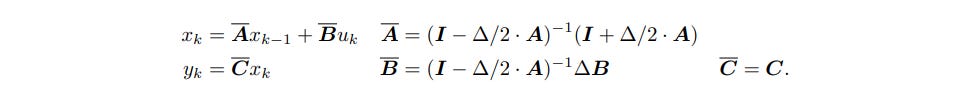
Now in the paper they doa few more steps to form a nice discrete time SSM which has low storage and time complexity, but the fundamental idea is that the SSM can compute long distance correlations as it is essentially a matrix which operates on the whole input, and thus can correlate farreaching parts of the input. The generated sound sequences on Sashimi are well worth listening to. While they’re still not that clear, they sound much better than before, and indicate how much progress is being made in the creation of music. In 2084, we might have robot musicians busking on the street.
