2084: Object Oriented LLMs: Better Tool Calling in LLMs and building Powerpoints with AI
How I learned to stop worrying and let AI build PowerPoints
So there I was, trying to get Claude to generate a comprehensive market research report with embedded charts, data tables, and proper formatting. The task seemed simple enough: research a topic, analyze the data, create visualizations, and compile everything into a professional Word document.
What I got back was this:
{
"function": "create_report",
"arguments": {
"title": "Market Analysis",
"content": "[REPORT CONTENT HERE]"
}
}Yeah, that wasn't going to work.
The Problem
While building various AI applications over the past year for fun, I kept hitting the same wall. I'd ask an AI to create a PowerPoint presentation about market trends, and it would either give me a JSON blob describing what the presentation should look like, or dump everything into a single massive Python function that tried to do everything at once.
Neither approach worked for complex, real-world documents; with multiple sections, embedded charts, tables with specific formatting, and all those little details that make a document professional.
Here's the thing - current tool-calling works nothing like how we actually use these libraries. When you create a PowerPoint presentation using python-pptx, you don't write one giant function. You do this:
# Step 1: Create the presentation
prs = Presentation()
# Step 2: Add a title slide
title_slide = prs.slides.add_slide(prs.slide_layouts[0])
title_slide.shapes.title.text = "Q4 Results"
# Step 3: Add a chart slide
chart_slide = prs.slides.add_slide(prs.slide_layouts[5])
# ... add chart
# Step 4: Save it
prs.save('presentation.pptx')It's object-oriented. It's stateful. It happens over multiple steps. And that's exactly what existing AI frameworks couldn't handle.

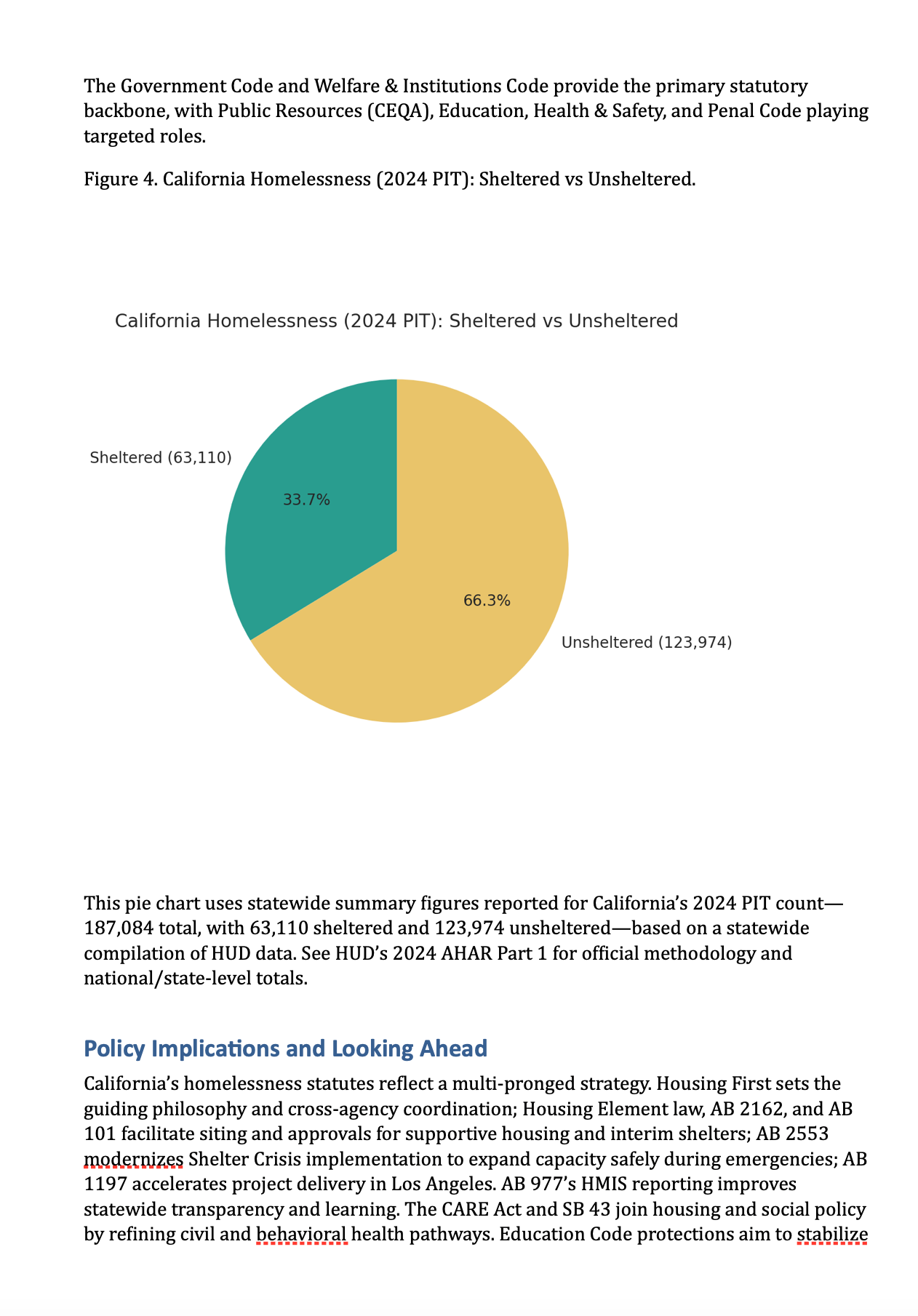
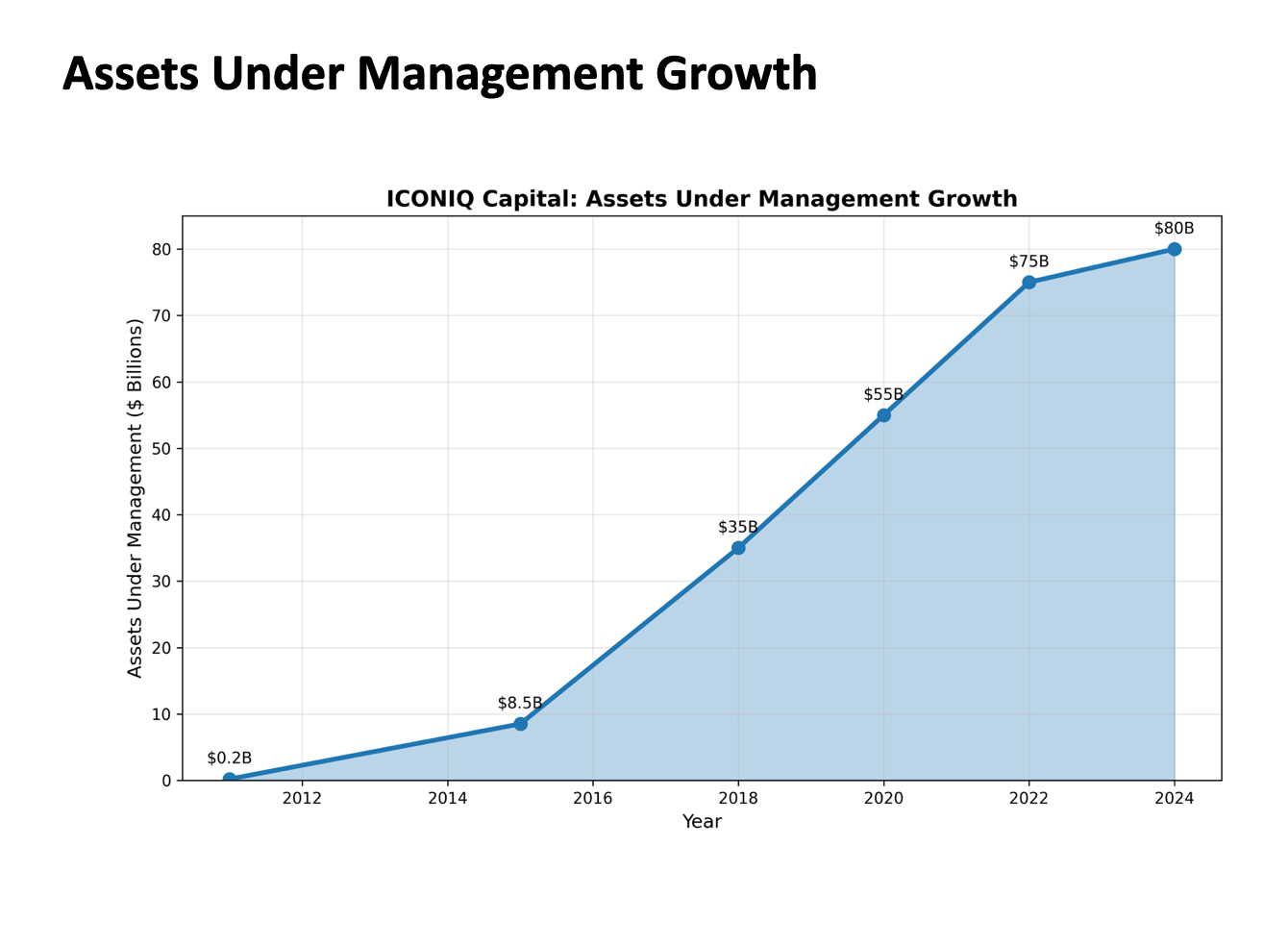
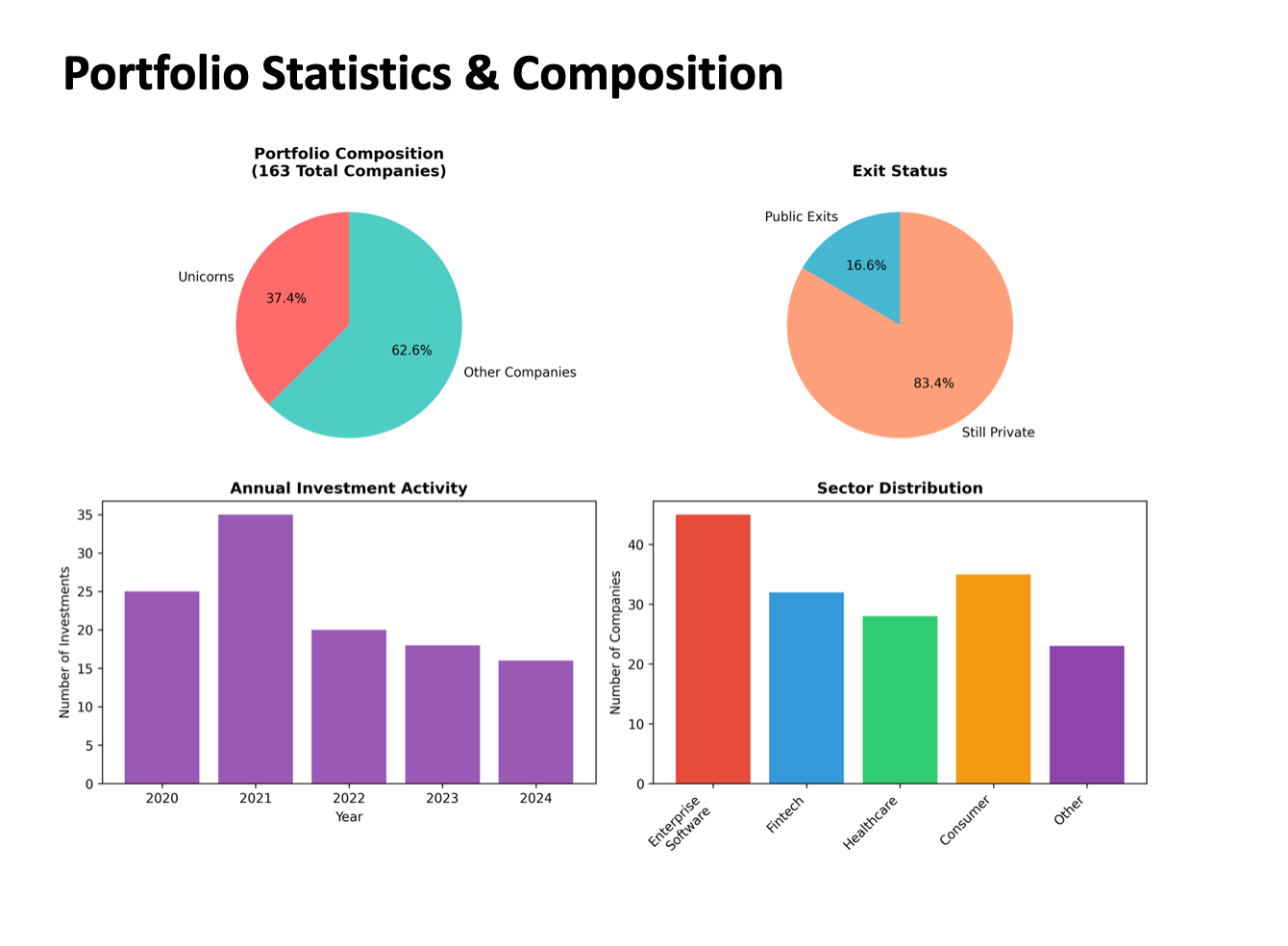
I even used it at a startup talk from Boom’s founder to generate a comprehensive account of the corporate history of Boom so I could understand more about what he was talking about. (Basically they have terrible unit margins)
The Two Approaches That Don't Work
Let me show you why both current approaches fail for real-world document generation.
Approach #1: JSON Function Calling
This is what OpenAI, Anthropic, and most other providers use. The AI generates a JSON object specifying what function to call:
json
{
"function": "create_document",
"arguments": {
"title": "Annual Report",
"sections": ["intro", "financials", "conclusion"]
}
}The problem? All the complexity gets pushed into the tool implementation. Want to add a chart between page 3 and 4? Too bad. Need custom formatting for one section? Not possible. The AI can only work with whatever rigid interface you've predefined.
It's like trying to paint the Mona Lisa by filling out a form.
Approach #2: Code Execution
The more sophisticated approach lets the AI write Python code:
# The AI writes something like this
doc = create_document("Annual Report")
add_section(doc, "Introduction", intro_text)
add_chart(doc, sales_data)
save_document(doc, "report.docx")Better, but still limited. The AI has to accomplish everything in a single code block. If something goes wrong halfway through, you start over. Want to iteratively refine the document based on intermediate results? Not happening.
Object Oriented LLM Toolcalling
While implementing document generation with python-docx and python-pptx, I had a realization. These libraries already have beautiful object-oriented interfaces that encourage multi-step, stateful interactions.
For example, creating a PowerPoint presentation with python-pptx naturally follows this pattern:
# Step 1: Create presentation object
prs = Presentation()
# Step 2: Add title slide
title_slide_layout = prs.slide_layouts[0]
slide = prs.slides.add_slide(title_slide_layout)
title = slide.shapes.title
title.text = "My Presentation"
# Step 3: Add content slide
bullet_slide_layout = prs.slide_layouts[1]
slide = prs.slides.add_slide(bullet_slide_layout)
shapes = slide.shapes
title_shape = shapes.title
title_shape.text = 'Key Points'
# Step 4: Add bullet points
body_shape = shapes.placeholders[1]
tf = body_shape.text_frame
tf.text = 'First important point'
p = tf.add_paragraph()
p.text = 'Second important point'
# Step 5: Save the presentation
prs.save('presentation.pptx')This multi-step, object-oriented approach is natural for humans and results in clean, maintainable code. But traditional tool calling frameworks couldn't support this pattern because they lacked state persistence between steps.
That's when it hit me: what if the LLM could act as a client to these object-oriented libraries, instantiating objects and calling methods on them across multiple reasoning steps?
I call this the notebook
Introducing the Maximum Agents Framework
The Maximum Agents framework was born from this insight. Instead of forcing everything into functional calls or single code blocks, it allows LLMs to:
Instantiate objects and maintain references to them
Call methods on these objects across multiple steps
Build complex artifacts incrementally through stateful interactions
Leverage existing object-oriented libraries without modification
Architecture Overview: The BaseAgent
At the core is the BaseAgent class, which orchestrates the interaction between the LLM and tools:
class BaseAgent[T: BaseModel](AbstractAgent):
def __init__(self,
system_prompt: str,
tools: list[Tool],
additional_authorized_imports: list[str],
final_answer_model: type[T] = BasicAnswerT,
model: str = "anthropic/claude-sonnet-4-20250514",
max_steps: int = 35,
hook_registry: Optional[HookRegistry] = None):
# ... initialization codeThe BaseAgent manages the entire lifecycle - from receiving a task, to multiple reasoning steps with tool calls, to returning structured output. Here's the key: it builds on top of smolagents' CodeAgent (huge shout-out to the Hugging Face team for their brilliant stateful Python execution system!), but takes full advantage of their stateful execution.
class CodeAgent(MultiStepAgent):
def create_python_executor(self) -> PythonExecutor:
# Using smolagents' LocalPythonExecutor for stateful execution
return LocalPythonExecutor(
self.additional_authorized_imports,
max_print_outputs_length=self.max_print_outputs_length
)
def _step_stream(self, memory_step: ActionStep):
# Parse LLM output for code
code_action = parse_code_blobs(output_text, self.code_block_tags)
# Execute code while maintaining state (thanks smolagents!)
code_output = self.python_executor(code_action)
# Return results
yield ActionOutput(output=code_output.output, is_final_answer=code_output.is_final_answer)Without smolagents' stateful execution model, object-oriented tool calling wouldn't be possible - each code block would execute in isolation, making it impossible to build complex objects incrementally.
For the agentic part, it uses a ReAct (Reasoning + Acting) loop where the LLM alternates between thinking and executing code. Every step is captured with structured logging:
class PartType(str, Enum):
THINKING = "thinking" # LLM reasoning and planning
CODE = "code" # Python code execution
OUTPUT = "output" # Execution results and tool outputs
TOOL_CALL = "tool_call" # Tool invocations with arguments
class StepT(BaseModel):
step_number: Optional[int] = None
parts: list[PartT] # Can contain multiple part types per stepThis structured approach lets you track exactly what the agent is thinking, what code it's executing, and what results it gets at each step. No more parsing raw text logs.
In addition, you define exactly what the agent should return using Pydantic models via the final_answer_model parameter:
agent = builder.build_agent(
system_prompt="...",
final_answer_model=YourCustomModelT, # Define the expected output structure
# ... other params
)
# Run with step monitoring
def monitor_progress(step: StepT):
for part in step.parts:
if part.type == "THINKING":
print(f"Planning: {part.content[:80]}...")
elif part.type == "CODE":
print(f"Executing: {part.content.split()[0]}...")
elif part.type == "OUTPUT":
print(f"Result: {part.content[:60]}...")
result = agent.run(
"Analyze the electric vehicle market trends for 2025 and create a comprehensive report with charts",
step_callback=monitor_progress
)
answer = result.answer # Strongly typed based on your modelThe agent's final output is automatically wrapped in a ResultT container and accessible through result.answer. This means you get exactly what you expect, with full type safety.
Tool Definition: Objects, Not Functions
A key difference in Maximum Agents is how tools are defined. Instead of functions that return data, tools return actual objects:
class GetDocumentTool(Tool):
name = "get_document"
description = "Creates and returns a Word document object"
inputs = {}
output_type = "object"
def forward(self) -> Document:
return Document() # Returns python-docx Document object
class GetPresentationTool(Tool):
name = "get_presentation"
description = "Creates and returns a PowerPoint presentation object"
inputs = {}
output_type = "object"
def forward(self) -> Presentation:
return Presentation() # Returns python-pptx Presentation objectNotice how these tools return objects that the LLM can interact with across multiple steps. When the AI calls doc = get_document(), it gets an actual Document object that persists in memory, not just a reference or ID.
How Maximum Agents Actually Works
Here's the key innovation: instead of executing code in isolation, we maintain state between the AI's reasoning steps. When the AI creates a document object in step 1, that same object is available in steps 2, 3, and beyond.
Let me show you what this looks like in practice. Here's an actual trace from the system creating a research report:
# Step 1: The AI does research
search_results = web_search("semiconductor export restrictions 2025")
# [AI reads results, formulates next search]
# Step 2: Create document (object persists!)
doc = get_document()
doc.add_heading('Semiconductor Export Restrictions: Strategic Analysis', 0)
# Step 3: Add executive summary (doc still available!)
doc.add_heading('Executive Summary', level=1)
summary = """Based on my research, the new restrictions primarily target
advanced node semiconductors..."""
doc.add_paragraph(summary)
# Step 4: Create visualization (doc still there!)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
affected_companies = ['NVIDIA', 'AMD', 'Intel', 'TSMC']
impact_scores = [85, 72, 45, 90]
plt.bar(affected_companies, impact_scores)
plt.title('Export Restriction Impact by Company')
plt.savefig('impact_chart.png')
# Step 5: Add chart to document (same doc object!)
doc.add_picture('impact_chart.png', width=Inches(6))
# Step 6: Continue building document...
doc.add_heading('Detailed Analysis', level=1)
# ... more content
# Step 7: Save final document
doc.save('semiconductor_export_analysis.docx')The magic is that doc persists across all these steps. The AI can build complex documents iteratively, just like a human would.
The Technical Magic: Stateful Execution with smolagents' LocalPythonExecutor
You might be wondering: how do we maintain state between execution steps? Here's where I need to give credit where it's due - the brilliant LocalPythonExecutor from smolagents (Hugging Face's agent framework) is what makes this all possible.
The smolagents team solved the hard problem of stateful Python execution. Instead of restarting the Python interpreter between code blocks, their LocalPythonExecutor maintains state across calls. But it's not just about keeping a dictionary around - they built a sophisticated system that safely executes arbitrary Python code while maintaining state by parsing everything through Python's Abstract Syntax Tree (AST) and writing custom evaluation functions for each node type.
Here's what smolagents' LocalPythonExecutor does under the hood:
class LocalPythonExecutor:
def __init__(self):
self.state = {"__name__": "__main__"} # This persists across all calls!
def __call__(self, code_action: str) -> CodeOutput:
# Parse the code into an AST - no direct exec()!
expression = ast.parse(code_action)
# Execute each AST node with custom evaluator
for node in expression.body:
result = evaluate_ast(node, self.state, self.static_tools,
self.custom_tools, self.authorized_imports)
return CodeOutput(output=result, logs=self.state["_print_outputs"])The magic is in smolagents' evaluate_ast function. Instead of using Python's dangerous eval() or exec(), they traverse the AST themselves and execute each node type with custom logic, maintaining state after each execution. This gives us:
Security: We can block access to dangerous functions like
os.system()or__import__State preservation: All variables, objects, and function definitions persist in
self.stateImport control: Only whitelisted libraries can be imported
Operation counting: We can prevent infinite loops by limiting operations
Here's what happens when the AI creates a document across multiple steps:
Step 1 execution:
# AI writes: doc = get_document()
# State after: {'doc': <Document object at 0x...>, '__name__': '__main__', ...}Step 2 execution:
# AI writes: doc.add_heading('Title', 0)
# The 'doc' object is still in state from Step 1!The executor also manages three types of objects:
Static Tools: Core functions that can't be overwritten (
get_document(),print(), math functions)Custom Tools: User-defined functions that can be modified during execution
State Variables: Everything the AI creates during execution
def send_tools(self, tools: dict[str, Tool]):
# Combine all tool types
self.static_tools = {**tools, **BASE_PYTHON_TOOLS.copy(), **self.additional_functions}
def send_variables(self, variables: dict[str, Any]):
# Add variables to persistent state
self.state.update(variables)Security Without Sacrificing Power
The AST evaluation approach that smolagents built gives us fine-grained security control. They figured out how to block dangerous operations while allowing legitimate document manipulation:
def evaluate_ast(node, state, static_tools, custom_tools, authorized_imports):
if isinstance(node, ast.Import):
# Check if import is authorized
for alias in node.names:
if alias.name not in authorized_imports:
raise InterpreterError(f"Import {alias.name} not authorized")
elif isinstance(node, ast.Attribute):
# Block access to dangerous dunder methods
if node.attr.startswith('__') and node.attr != '__name__':
raise InterpreterError(f"Access to {node.attr} is not allowed")
# ... handle other node typesThis is how we can give the AI access to powerful libraries like pandas and matplotlib without worrying about it accidentally (or intentionally) running os.system('rm -rf /'). The smolagents team did the hard work of making Python execution both stateful and safe - I just had to figure out how to use it for object-oriented tool calling.
Workspaces: Where Files Actually Live
One thing I learned the hard way: when AI agents create files, you need to know where those files end up(I have like 70 random docx in my downloads folder) That's why Maximum Agents treats workspaces as first-class concepts.
Every agent operates in its own workspace directory:
# Create agent in specific workspace
builder = AgentBuilder()
builder.put_agent_in_specific_dir("/workspaces/research_123")
# All files created by this agent go here
agent = builder.build_agent(...)This solves several problems:
Files don't scatter across your filesystem
Multiple agents can work in parallel without conflicts
Easy cleanup when a task completes
The frontend knows exactly where to find generated documents
It's one of those obvious-in-retrospect design decisions that makes everything else easier.
In addition, if you use a DocumentT as the output, it automagically resolves the path to the real document.
class DocumentT(BaseModel):
path: str = Field(description="File path of generated document")
explanation: str = Field(description="What the document contains")
absolute_path: Optional[str] = Field(default=None)
def model_post_init(self, __context: Optional[dict[str, Any]]) -> None:
# Automatically resolve paths to absolute paths
if self.absolute_path is None:
if isinstance(__context, dict) and 'document_finder' in __context:
document_finder = __context['document_finder']
self.absolute_path = document_finder(self.path)
else:
self.absolute_path = os.path.abspath(self.path)
class DocumentsT(BaseModel):
documents: List[DocumentT] = Field(description="Generated documents")Real Results: MaximumResearch
To prove this approach, I built MaximumResearch - a full-stack application where users can request complex research and get back professional documents. Not templates. Not outlines. Actual Word documents and PowerPoint presentations with charts, tables, and formatting.
Here's what happens when you request that it "analyze the smartphone market and create a presentation":
Research Phase: The agent searches for market data, competitor analysis, and trends
Analysis Phase: It processes the data, identifies key insights
Visualization Phase: Creates charts using matplotlib
Document Creation Phase: Builds a PowerPoint with:
Title slide with professional formatting
Market overview with bullet points
Competitive analysis with embedded charts
Trend projections with data tables
Conclusion with key takeaways
The entire process is visible in real-time through the React frontend. Users see each reasoning step, can download intermediate outputs, and get a professional presentation at the end. Check it out .
Database Integration: Not Just Documents
The framework isn't limited to documents. You can give agents database access too:
def add_database(self, datastore: MaximumDataStore, database_id: str) -> 'AgentBuilder':
"""Add database capabilities to the agent within the workspace context."""
self._datastore = datastore
self._database_id = database_id
sql_tool = DatabaseTool(database_id, datastore)
self.additional_tools.append(sql_tool)
return selfNow the agent can combine SQL queries with document generation:
# Step 1: Query database
sales_data = pd.read_sql("SELECT * FROM sales WHERE date >= '2024-01-01'", engine)
# Step 2: Analyze data
monthly_trends = sales_data.groupby('month').sum()
# Step 3: Create visualization
plt.figure(figsize=(12, 8))
monthly_trends.plot(kind='bar')
plt.savefig('sales_trends.png')
# Step 4: Generate report with findings
doc = get_document()
doc.add_heading('Sales Analysis Report', 0)
doc.add_picture('sales_trends.png', width=Inches(6))
# Step 5: Add data table directly from SQL results
table = doc.add_table(rows=len(monthly_trends)+1, cols=2)
for i, (month, sales) in enumerate(monthly_trends.iterrows()):
table.rows[i+1].cells[0].text = str(month)
table.rows[i+1].cells[1].text = f'${sales:,.2f}'
doc.save('sales_analysis.docx')The agent can work with both file-based outputs and structured data within the same workspace context. This enables workflows that would be impossible with traditional tool calling.
Comparing Approaches: A Concrete Example
Here’s how different approaches handle "Create a quarterly report with financial charts":
JSON Approach:
{"function": "create_quarterly_report", "arguments": {"quarter": "Q4"}}The tool has to handle everything internally with no flexibility.
Single Code Block:
data = load_financial_data("Q4")
create_all_charts(data)
generate_report_with_charts("Q4_report.docx")Everything must work perfectly in one shot.
Maximum Agents:
# Step 1: Load and analyze data
financial_data = load_financial_data("Q4")
print(f"Revenue: ${financial_data['revenue']:,}")
# Step 2: Create document
doc = get_document()
doc.add_heading('Q4 Financial Report', 0)
# Step 3: Add summary
if financial_data['revenue'] > financial_data['target']:
doc.add_paragraph('Q4 exceeded targets!').bold = True
else:
doc.add_paragraph('Q4 performance below expectations')
# Step 4: Generate chart based on data patterns
create_revenue_chart(financial_data)
doc.add_picture('revenue_chart.png', width=Inches(6))
# Step 5: Add detailed analysis
# ... continues iterativelyThe AI can make decisions based on intermediate results, handle errors, and build what's needed.
Document Generation Example
Here's a complete example using DocumentT for file generation:
from maximum_agents import AgentBuilder, DocumentsT, DocumentT, WebSearchTool, GetDocumentTool, GetPresentationTool
from maximum_agents.records import StepT
import matplotlib
from pydantic import BaseModel, Field
from typing import List
matplotlib.use('Agg') # Use non-GUI backend for matplotlib
class ResearchOutput(BaseModel):
executive_summary: str = Field(description="Key findings summary")
methodology: str = Field(description="Research approach used")
main_document: DocumentT = Field(description="Primary research report")
supporting_charts: List[DocumentT] = Field(description="Generated visualizations")
confidence_score: float = Field(description="Research confidence (0-1)")
# Build agent with workspace and tools
builder = AgentBuilder()
builder.put_agent_in_specific_dir("/content/analysis")
builder.add_additional_tools([WebSearchTool(), GetDocumentTool(), GetPresentationTool()])
# Create agent with complex structured output
agent = builder.build_agent(
system_prompt="You are a research analyst who creates comprehensive reports with visualizations.",
additional_authorized_imports=["matplotlib", "pandas", "docx", "pptx", "numpy", "matplotlib.pyplot", "pptx.util"],
final_answer_model=ResearchOutput, # Complex output model
final_answer_description="A comprehensive report with charts",
max_steps=25
)
# Run with step monitoring
def monitor_progress(step: StepT):
for part in step.parts:
if part.type == "THINKING":
print(f"Planning: {part.content[:80]}...")
elif part.type == "CODE":
print(f"Executing: {part.content.split()[0]}...")
elif part.type == "OUTPUT":
print(f"Result: {part.content[:60]}...")
result = agent.run(
"Analyze the electric vehicle market trends for 2025 and create a comprehensive report with charts",
log=monitor_progress
)
# Access structured results with automatic path resolution
research_output = result.answer
print(f"Summary: {research_output.executive_summary}")
print(f"Main report: {research_output.main_document.absolute_path}")
print(f"Charts generated: {len(research_output.supporting_charts)}")
Conclusion
I think that shifting from functional to object-oriented tool calling will do the same thing it did for human engineers: Let AI agents work with tools the same way humans do - incrementally, with state, over multiple steps and unlock their ability to create complex, professional outputs.
Next time you need an AI to create something complicated, ask yourself: are you forcing it to paint the Mona Lisa by filling out a form? Or are you giving it an paintbrush?
The future in 2084 will be AI agents that can think, plan, and build incrementally. Just like we do.
Try it out! Here is a colab for the above code. Here is the github for maximum agents.