

2084: MarcRandbot: Speech Synthesis with Mamba
Using Mamba to do speech synthesis.

After using the new transformer competitor Mamba, to emulate Shakespeare, I wondered if I could use it for speech synthesis. They mentioned it in the original paper, but I couldn’t find the actual models, and besides, it was a fun exercise to try to do it for myself. This blogpost will be about how I went about using Mamba for speech synthesis, focusing on the dataset, tokenizer and models.
All the code is in this colab.
Dataset
First I started with the dataset - the audio on which this was trained. I wanted to make my own, just for fun. I think a lot of posts don’t elaborate on how they created the dataset enough, and it is by far the most important part of the whole training pipeline in a sense.
So I’ve always been a big fan of Marc Randolph, the Netflix entrepreneur, and I had a friend who knows the guy, so I thought: hey, I’m going to make the MarcRandbot. So I looked on Youtube and found that he had a podcast:
It’s pretty good, would recommend. Anyway, with this I had all the data I would need for my MarcRandbot.
To download the videos from the playlists, I used pytube, which is an awesome tool for downloading Youtube videos for projects. Used it a bunch. Following is the code for downloading all the audiostreams from a playlist to an folder audio/:
from pytube import Playlist
def download_audio_from_playlist(playlist_url, output_path):
playlist = Playlist(playlist_url)
for video in playlist.videos:
audio_stream = video.streams.get_audio_only()
audio_stream.download(output_path=output_path, filename=video.title + ".mp4")
playlist_url = "<playlist_url>"
download_audio_from_playlist(playlist_url, 'audio/')However, this produces files with the extension .mp4, and for most applications, we want wav. In addition, these are 4 hour videos: we want to cut them up shorter for training purposes. Thus I decided to divide the videos all into 10 second increments, using moviepy:
from moviepy.editor import AudioFileClip
import os
def convert_mp4_to_wav_clips(mp4_file, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Convert mp4 to wav and split into 10-second clips
# Load the audio from the video file
audio = AudioFileClip(mp4_file)
# Duration of the audio in seconds
duration = int(audio.duration)
# Split the audio into 10-second clips and save
mp4_output_name = os.path.basename(mp4_file).split('.')[0].replace(' ', '_').replace("#", "num")
print(mp4_output_name)
for start in range(0, duration, 10):
outputpath = os.path.join(output_dir, f'{mp4_output_name}_clip_{start}_{start+10}.wav')
if os.path.exists(outputpath):
continue
end = min(start + 10, duration)
clip = audio.subclip(start, end)
clip.write_audiofile(outputpath, verbose=False, logger=None)
message = "Conversion and splitting successful."
print(message)
import os
from tqdm import tqdm
def get_audio_files(directory):
return [os.path.join(directory, file) for file in os.listdir(directory) if file.endswith('.mp4')]
audio_files = get_audio_files('MarcBot')
print(audio_files)
for af in tqdm(audio_files):
convert_mp4_to_wav_clips(af, 'MarcBotClips')Now I had a folder of 10000 10 second clips in MarcBotClips.
Tokenizer
Now I had to turn this into something which could be predicted with a transformer. First I tried using Encodec from the AudioLM github, but the resulting tokens did not sound that great, and I also had to deal with seperate semantic and acoustic tokenizers1. But then I found the SpeechTokenizer paper, which combines the two into one, having the first codebook be semantic and the rest be acoustic tokens.

Now, before I go on, read residual vector quantization, as this explains how the tokens are generated. Basically, its the following algorithm as applied to vertical slices (columns) from an audio spectrogram, i.e., a list of amplitudes for a set of frequencies that were found over a short time interval called a “frame.”:
def quantizer(data, codebooks, n_grid=5):
"this will spit out indices for residuals in a series of 'nested' codebooks"
resids = data
indices = []
for cb in codebooks:
indices_l = get_region_membership(resids, codebook=cb)
resids = resids - cb[indices_l]
indices.append(indices_l)
return np.array(indices)
# Make the nested codebooks
n_codebooks = 3
codebook = generate_codebook(n_grid)
codebooks = [codebook/n_grid**level for level in range(n_codebooks)]
indices = quantizer(data, codebooks) # call the quantizer
display(indices)This essentially creates a 2 dimensional array, where the first dimension is the number of codebooks, which is essentially the “resolution” at which the vectors are quantized, and the second is a time domain, representing the original audio divided into frames. (or to be exact, representing the result of applying 1-dimensional convolution neural networks to the original audio for some additional compression.)
Now, SpeechTokenizer essentially just modifies this by modifying the loss function, to have the first codebook be bound with a semantic loss function in addition to the typical RVQ reconstruction loss problem. See the paper for more details, it’s fairly complex.
So I used the SpeechTokenizer models that they provided, which worked fairly well.
Anyways, so having our tokenizer in hand, you’d think we could just apply it to the audio directly. But first, normalization is important - otherwise you get errors and errors. (there was a lot of trial and error in this step). I essentially flattened the audio and converted it to the right sampling rate for the model. In addition, I used the huggingface datasets library - really cool library, lets you load all the audio files from an given folder into a dataset which can be manipulated.
But I kept running into this issue where the map for the dataset would randomly freeze up and take forever, which I worked out was that it would write the entire dataset to cache at certain points in the process, which took forever as it was a fairly large dataset. As the whole dataset could fit within the RAM in my PC however, I decided to up the writer_batch_size to more than the number of samples I had, to prevent this issue. And now without further ado, the code:
from speechtokenizer import SpeechTokenizer
import torchaudio
import torch
from datasets import load_dataset
# Load pretrained speech tokenizer models.
config_path = "./speechtokenizermodel/speechtokenizer_hubert_avg_config.json"
ckpt_path = "./speechtokenizermodel/SpeechTokenizer.pt"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
speech_tokenizer = SpeechTokenizer.load_from_checkpoint(config_path, ckpt_path).to(device)
speech_tokenizer.eval()
# The number of codebooks I took from the full amount to encode the audio.
NUM_QUANTIZERS_USED = 4
# Taking the mean to combine channels together and then resampling from the original sampling rate to the one that speech tokenizer requires
def normalize_waveform(waveform, sr):
if len(waveform.shape) == 2 and waveform.shape[1] > 0:
waveform = torch.mean(waveform, dim=0, keepdim=True)
waveform = waveform.reshape(1, -1)
waveform = torchaudio.functional.resample(waveform, sr, speech_tokenizer.sample_rate)
return waveform
# Expected input: waveform of shape (B, C, V)
# The encoding returns shape (num codebooks, 1, timestep). Using it with batch size > 1 gave me a lot of errors so I didn't try it.
# After encoding the tokens, I threw away some of the later codebooks which encode less information before I flattened them as explained below.
def tokenize(waveform):
print(waveform.shape)
with torch.no_grad():
codes = speech_tokenizer.encode(waveform.unsqueeze(0).to(device)) # codes: (n_q, B, T)
semantic_tokens = codes[:NUM_QUANTIZERS_USED, :, :].cpu()
print("semantic_tokens.shape",semantic_tokens.shape)
return flatten_tokens(semantic_tokens)
def save_waveform(filename, waveform):
torchaudio.save(filename, waveform[0].detach().cpu(), 16000)
def decode_tokens(tokens):
unflattened_tokens = unflatten_tokens(tokens)
return speech_tokenizer.decode(unflattened_tokens)
def save_to_file(tok, filename):
print(tok.shape)
outputwav = decode_tokens(tok.detach().to(device))
print(outputwav)
save_waveform(filename, outputwav)
# Transposing the timestep and code books before flattening to have it be a1, b1, c1 instead of a1, a2, a3, b1, b2, b3, since I'm throwing away some of the codebooks, and I also want to be able to generate based on timestep
def flatten_tokens(tokens):
n_q, B, T = tokens.shape
transpose_tokens = tokens.transpose(0, 2)
print("transpose_tokens.shape", transpose_tokens.shape)
return transpose_tokens.reshape(B, T * NUM_QUANTIZERS_USED)
# Inverting the flatten and transpose
def unflatten_tokens(tokens):
B, L = tokens.shape
T = L // NUM_QUANTIZERS_USED
return tokens.reshape(T, B, NUM_QUANTIZERS_USED).transpose(0, 2)
# Testing speech_tokenizer
# Path to the input audio file
input_file_path = "testtest.wav"
# Path to the output audio file
output_file_path = "out.wav"
# Testing the speechtokenizer and flatten, unflatten tokens to see if it works
waveform, sample_rate = torchaudio.load(input_file_path)
waveform = torch.mean(waveform, dim=0, keepdim=True)
waveform = torchaudio.functional.resample(waveform, sample_rate, speech_tokenizer.sample_rate)
# Write the waveform to a new file
print(waveform.shape)
torchaudio.save(output_file_path, waveform, sample_rate)
# Extract discrete codes from SpeechTokenizer
with torch.no_grad():
codes = speech_tokenizer.encode(waveform.unsqueeze(0).to(device)) # codes: (n_q, B, T)
semantic_tokens = codes[:NUM_QUANTIZERS_USED, :, :]
acoustic_tokens = codes[1:, :, :]
print(semantic_tokens.shape)
print(semantic_tokens.transpose(0, 2).reshape(1, 500 * 4))
waveform = speech_tokenizer.decode(semantic_tokens)
print(waveform.shape)
torchaudio.save(output_file_path, waveform[0].detach().cpu(), speech_tokenizer.sample_rate)
assert torch.allclose(
unflatten_tokens(flatten_tokens(semantic_tokens)), semantic_tokens
)
#
waveform, sample_rate = torchaudio.load(input_file_path)
waveform = normalize_waveform(waveform, sample_rate)
semantic_tokens = tokenize(waveform)
save_to_file(semantic_tokens, "out2.wav")
print("Loading Dataset")
# Select subset from MarcBotClips
audio_dataset = load_dataset("audiofolder", data_dir="MarcBotClips")["train"].select(
range(0, 9000)
)
print("Normalizing the waveforms")
audio_dataset = audio_dataset.map(
lambda x: {
"original_sampling_rate": x["audio"]["sampling_rate"],
"audio_array": normalize_waveform(
torch.tensor(x["audio"]["array"]), x["audio"]["sampling_rate"]
),
},
remove_columns=["audio"],
# keep_in_memory=True,
writer_batch_size=15000,
)
print(audio_dataset.column_names)
print(len(audio_dataset[0]["audio_array"]), torch.tensor(audio_dataset[0]["audio_array"]).shape)
print("Tokenizing the waveforms")
audio_dataset = audio_dataset.filter(
lambda x: len(x["audio_array"][0]) == 160000,
)
print("Tokenizing the waveforms")
audio_dataset = audio_dataset.map(
lambda x: {"tokens": tokenize(torch.tensor(x["audio_array"]))
},
remove_columns=[
"audio_array",
],
writer_batch_size=15000,
)
print(audio_dataset.column_names)
audio_dataset.push_to_hub("GeneralRincewind/MarcBotSpeechTokenizerDataset", private=True)
# Checking the files to see if the tokenization worked correctly.
for idx, t in enumerate(audio_dataset.select(range(0, 10))):
save_to_file(torch.tensor(t["tokens"]).to(device), f"testfiles/{idx}_test.wav")
So for the actual structure of the tokens, I decided to arrange it such that it was linear, so that the mamba transformer could predict it, but in the following fashion, where a,b,c indicate tokens from different codebooks: a1, b1, c1, a2, b2, c2. There is an interesting point here however: in the interest of reducing the size of the vocab, I decided to not modify the indices of the codebooks, leaving each token from a, b, c in the original 0-1024 range. What this means in practice is that, if a given timestep had the same codebook index 0 for all the 4 codebooks, it would be represented as 0,0,0,0, with nothing to differetiate which codebook it came from. I thought that the positional encoding of the transformer would be enough to distinguish this, however this is still something I’d like to test to see what the resulting quality would be.
I also didn’t use all the codebooks to have the resulting string be shorter, only using the first 4, which I determined to have resulted in an acceptable loss in quality.
Now after, this processing, as you can see above I uploaded the dataset to huggingface. One unexpected benefit of the tokenization was that after processing, my 20GB dataset had become something like 45 MB, which made uploading and working with it much easier.
Model
After this, I used Mamba on the flattened tokens, to do next token prediction, with an architecture based on Karparthy’s NanoGPT. My target was just the token shifted one across. It seemed to work pretty well. All the code is in this colab, if you want to check it out. I used weights and biases to record it. I also did a test train split of about 95%. For testing purposes, I took some random audio files, and took the first half and asked the model to complete it.
After a lot of training(42000 steps), I did produce meaningful babbling that sounds somewhat correct!
Test Example:
Train Example:
Now an interesting next step would be to have this be conditioned on the transcript, to create a text to speech model, but that’s for later.
Now, Mamba really impressed me with this task. Despite my Mamba model having less parameters than my Transformer network2, it still performed really well, beating it out in convergence and eventual test loss.
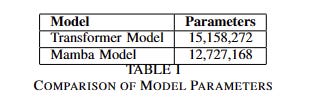
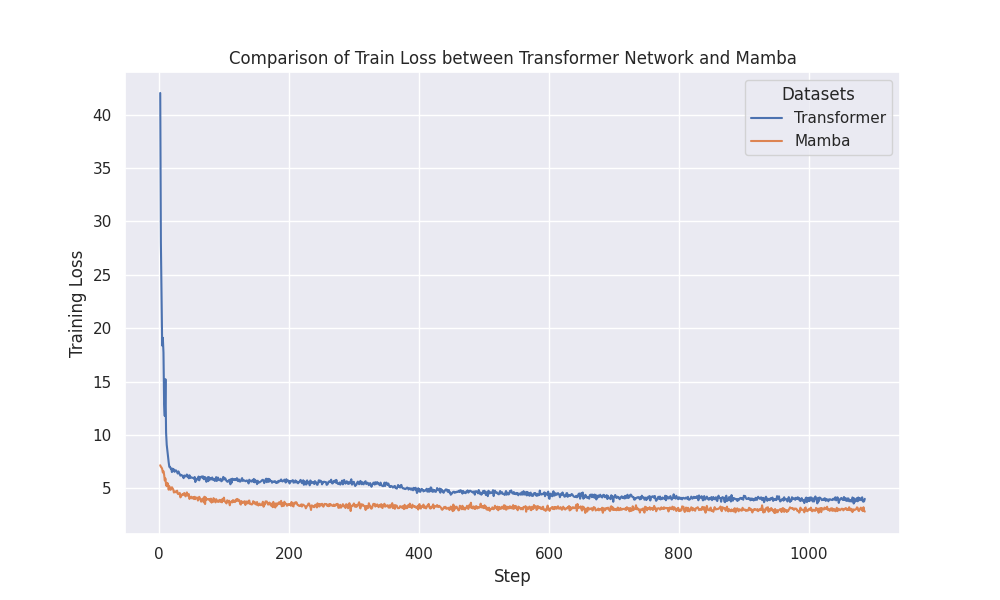

As you can see from this, Mamba beats out the transformers for this speech synthesis task. Beyond that, it was also really memory efficient, which was awesome for playing around on colab, where you continually run out of space on the GPUs. I think it’s a game changer in terms of performance and quality for transformer networks, and it’s a super simple switch - a Mamba block is literally a dropin replacement for a self-attention block.
It’s been a fun project, and I’m kinda interested in expanding on it more: Maybe building a full blown text to speech model, or even a speech to text model.
Or doing some sort of music generation model - maybe make a Led Zeppelin model. Subscribe if you’re interested!
in quick terms, semantic tokens encodes the meaning of audio, and acoustic tokens how it sounds
it’s fabulous, learning TTS would be awesome too
Fascinating.